AI Engineering / Architecture
SLM for RAG: The Edge Revolution in AI Engineering
Why small language models are the key to building fast, private, and cost-effective Retrieval-Augmented Generation (RAG) pipelines in 2026.
Written by

Codehouse Author
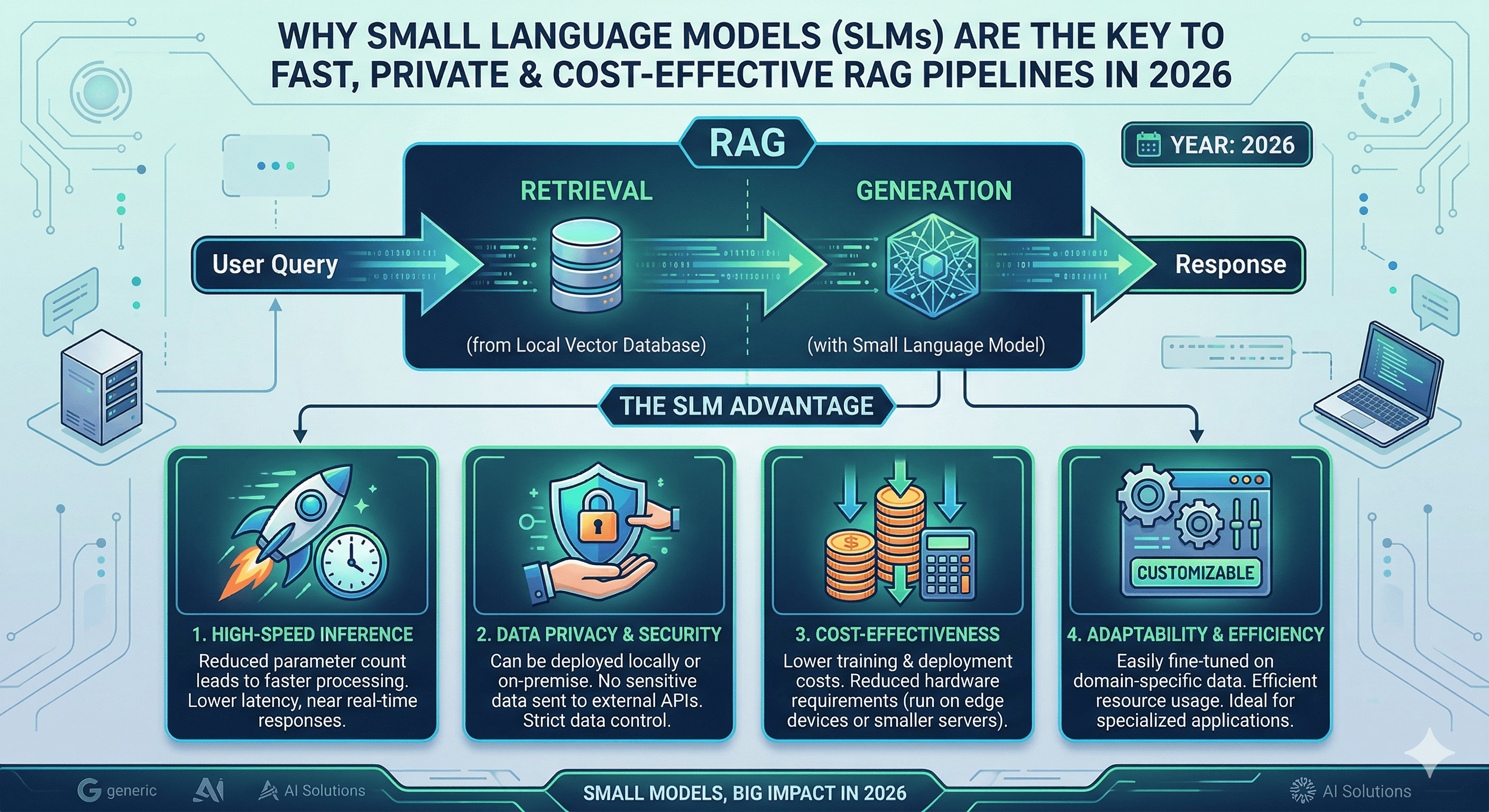
In the early days of generative AI, the mantra was "bigger is better." Organizations rushed to integrate massive models with hundreds of billions of parameters into their workflows. However, as we move through 2026, a significant architectural shift is occurring. Senior engineers are realizing that for specific, data-driven tasks, a SLM for RAG (Small Language Model for Retrieval-Augmented Generation) is often superior to its larger counterparts in terms of latency, cost, and security.
As we discussed in our exploration of the AI Agent Orchestrator, the role of the model in a RAG pipeline is not to know everything, but to be a precise "reasoner" over the provided context. When you provide a model with the exact documentation or data it needs to answer a query, the requirement for massive internal knowledge drops significantly. This is where SLM for RAG shines: it provides the intelligence needed to synthesize information without the "baggage" of a trillion parameters.
The Technical Case for Small Language Models
Why are we seeing such a surge in SLM for RAG adoption? The primary driver is "Contextual Efficiency." Models like Microsoft's Phi-4 or Apple's OpenELM are designed to perform exceptionally well on logic and reasoning tasks despite their smaller footprint. In a RAG setup, the "heavy lifting" of knowledge storage is handled by your vector database (like Milvus or Pinecone), while the SLM handles the final step of generating a coherent response based on the retrieved snippets.
This architecture aligns with the "Modular Monolith" and "Microservices" patterns we teach in our Advanced Node.js course. By decoupling the knowledge (data) from the reasoning (model), you create a system that is easier to update, audit, and scale. An SLM for RAG can be swapped or fine-tuned for a specific domain—such as legal or medical—without the prohibitive costs associated with fine-tuning a massive LLM.
Privacy and the "Local-First" Mandate
For many enterprises, the biggest barrier to AI adoption is data privacy. Sending sensitive proprietary data to a third-party API is a non-starter for many compliance teams. Using an SLM for RAG allows you to run the entire pipeline locally or within your private cloud. This ensures that your intellectual property never leaves your infrastructure, a concept we dive deep into in Shadow AI: The Invisible Risk.
Running SLM for RAG on-premises isn't just about security; it's about performance. By eliminating the round-trip time to a public API, you can achieve sub-second response times that are critical for interactive applications. Whether you are building a real-time coding assistant or a low-latency customer support bot, the "Edge" is where the competitive advantage lies in 2026.
The Rule of 4: SLM for RAG Use Cases
To help you visualize where this technology fits into your stack, here are four distinct scenarios where an SLM for RAG outperforms a general-purpose LLM:
On-Device Technical Support: Field engineers working in remote areas with limited connectivity can use a local SLM to query thousands of pages of technical manuals stored on their ruggedized tablets.
High-Throughput Log Analysis: Real-time monitoring systems that use RAG to compare current system logs against a database of "known issues" and "historical fixes" to suggest immediate remediation steps.
Privacy-Sensitive Document Review: Legal teams processing thousands of discovery documents where data sovereignty is mandated by law, ensuring that no "cloud leak" is even theoretically possible.
Cost-Effective Customer Chatbots: Handling millions of routine customer queries by retrieving answers from a knowledge base, reducing API costs by 90% compared to using "GPT-class" models for simple synthesis tasks.
Infrastructure Requirements for Local SLMs
Deploying an SLM for RAG requires a solid foundation in Linux engineering. You need to manage GPU/NPU resources, configure containerized inference engines like vLLM or Ollama, and ensure that your vector retrieval layer is highly available. As we emphasize in our Linux Mastery course, the shell is your primary interface for tuning these high-performance environments.
Mastering the command line allows you to monitor memory usage, optimize kernel parameters for low-latency networking, and secure the API endpoints that expose your local model to the rest of your architecture. In 2026, the best AI Engineers are also the best Systems Engineers.
The Future of Specialized Intelligence
The era of the "Generalist Model" is giving way to the era of "Specialized Agents." By leveraging SLM for RAG, you are building systems that are leaner, faster, and more aligned with the realities of production software engineering. You aren't just following a trend; you are optimizing for the long-term sustainability of your AI initiatives.
For a deeper look into the latest benchmarks of small language models, check out the Hugging Face SLM Benchmark Guide. The revolution won't be televised—it will be hosted on your own servers, running precisely what you need, exactly when you need it.
In the early days of generative AI, the mantra was "bigger is better." Organizations rushed to integrate massive models with hundreds of billions of parameters into their workflows. However, as we move through 2026, a significant architectural shift is occurring. Senior engineers are realizing that for specific, data-driven tasks, a SLM for RAG (Small Language Model for Retrieval-Augmented Generation) is often superior to its larger counterparts in terms of latency, cost, and security.
As we discussed in our exploration of the AI Agent Orchestrator, the role of the model in a RAG pipeline is not to know everything, but to be a precise "reasoner" over the provided context. When you provide a model with the exact documentation or data it needs to answer a query, the requirement for massive internal knowledge drops significantly. This is where SLM for RAG shines: it provides the intelligence needed to synthesize information without the "baggage" of a trillion parameters.
The Technical Case for Small Language Models
Why are we seeing such a surge in SLM for RAG adoption? The primary driver is "Contextual Efficiency." Models like Microsoft's Phi-4 or Apple's OpenELM are designed to perform exceptionally well on logic and reasoning tasks despite their smaller footprint. In a RAG setup, the "heavy lifting" of knowledge storage is handled by your vector database (like Milvus or Pinecone), while the SLM handles the final step of generating a coherent response based on the retrieved snippets.
This architecture aligns with the "Modular Monolith" and "Microservices" patterns we teach in our Advanced Node.js course. By decoupling the knowledge (data) from the reasoning (model), you create a system that is easier to update, audit, and scale. An SLM for RAG can be swapped or fine-tuned for a specific domain—such as legal or medical—without the prohibitive costs associated with fine-tuning a massive LLM.
Privacy and the "Local-First" Mandate
For many enterprises, the biggest barrier to AI adoption is data privacy. Sending sensitive proprietary data to a third-party API is a non-starter for many compliance teams. Using an SLM for RAG allows you to run the entire pipeline locally or within your private cloud. This ensures that your intellectual property never leaves your infrastructure, a concept we dive deep into in Shadow AI: The Invisible Risk.
Running SLM for RAG on-premises isn't just about security; it's about performance. By eliminating the round-trip time to a public API, you can achieve sub-second response times that are critical for interactive applications. Whether you are building a real-time coding assistant or a low-latency customer support bot, the "Edge" is where the competitive advantage lies in 2026.
The Rule of 4: SLM for RAG Use Cases
To help you visualize where this technology fits into your stack, here are four distinct scenarios where an SLM for RAG outperforms a general-purpose LLM:
On-Device Technical Support: Field engineers working in remote areas with limited connectivity can use a local SLM to query thousands of pages of technical manuals stored on their ruggedized tablets.
High-Throughput Log Analysis: Real-time monitoring systems that use RAG to compare current system logs against a database of "known issues" and "historical fixes" to suggest immediate remediation steps.
Privacy-Sensitive Document Review: Legal teams processing thousands of discovery documents where data sovereignty is mandated by law, ensuring that no "cloud leak" is even theoretically possible.
Cost-Effective Customer Chatbots: Handling millions of routine customer queries by retrieving answers from a knowledge base, reducing API costs by 90% compared to using "GPT-class" models for simple synthesis tasks.
Infrastructure Requirements for Local SLMs
Deploying an SLM for RAG requires a solid foundation in Linux engineering. You need to manage GPU/NPU resources, configure containerized inference engines like vLLM or Ollama, and ensure that your vector retrieval layer is highly available. As we emphasize in our Linux Mastery course, the shell is your primary interface for tuning these high-performance environments.
Mastering the command line allows you to monitor memory usage, optimize kernel parameters for low-latency networking, and secure the API endpoints that expose your local model to the rest of your architecture. In 2026, the best AI Engineers are also the best Systems Engineers.
The Future of Specialized Intelligence
The era of the "Generalist Model" is giving way to the era of "Specialized Agents." By leveraging SLM for RAG, you are building systems that are leaner, faster, and more aligned with the realities of production software engineering. You aren't just following a trend; you are optimizing for the long-term sustainability of your AI initiatives.
For a deeper look into the latest benchmarks of small language models, check out the Hugging Face SLM Benchmark Guide. The revolution won't be televised—it will be hosted on your own servers, running precisely what you need, exactly when you need it.



